Postgres Internal
Postgres database cluster is not like many database servers. It hosts on single server and contains multiple databases. Each database contains multiple indexes, tables and other objects. Databases, tables, indexes files are all objects, and are uniquely identified with an OID.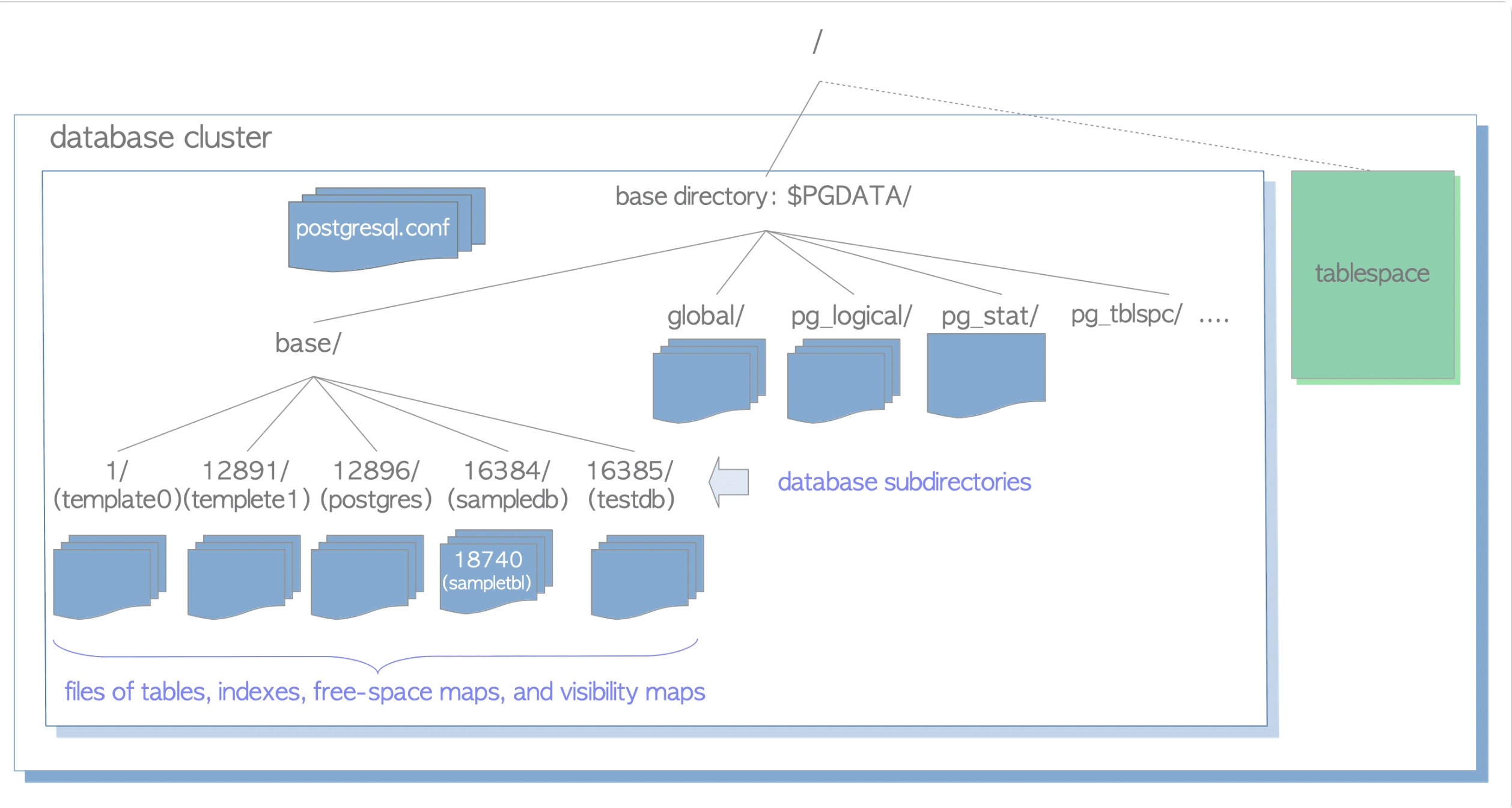
Its storage is like a file system. All the files except for tablespace are stored in base directory, specified by $PGDATA. Database subdirectories are named as their OIDs.
Inside database, tables and index files are initially 1GB file named as their reffilenode, or serveral 1GB files named as reffilenode.x if it gets larger size.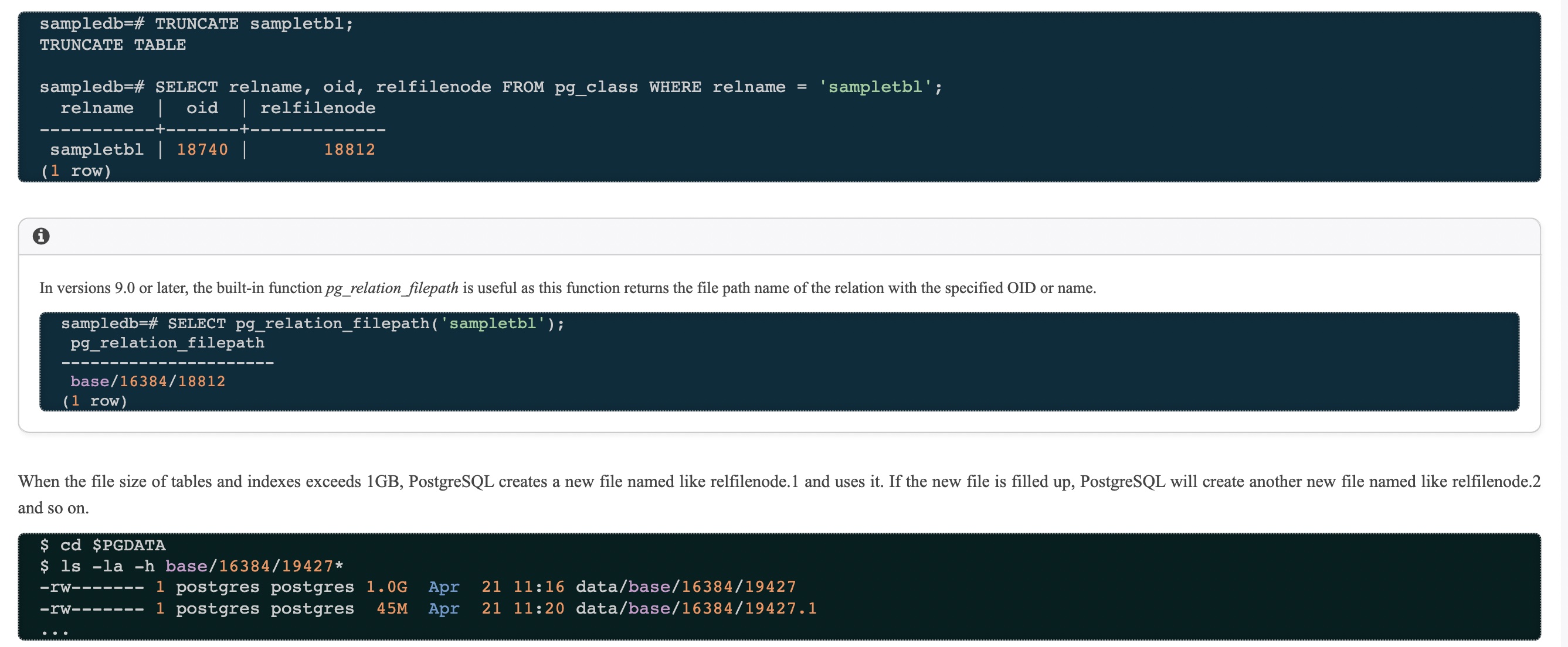
Besides, each table also associates with two files with suffix _fsm and _vm. They are free space map and visibility map.
- The free space map stores free space of each page within the table file. It is related to concurrency control.
- The visibility map stores the visibility of each page within the table file. It is related to Vaccum processing.
Table Storage
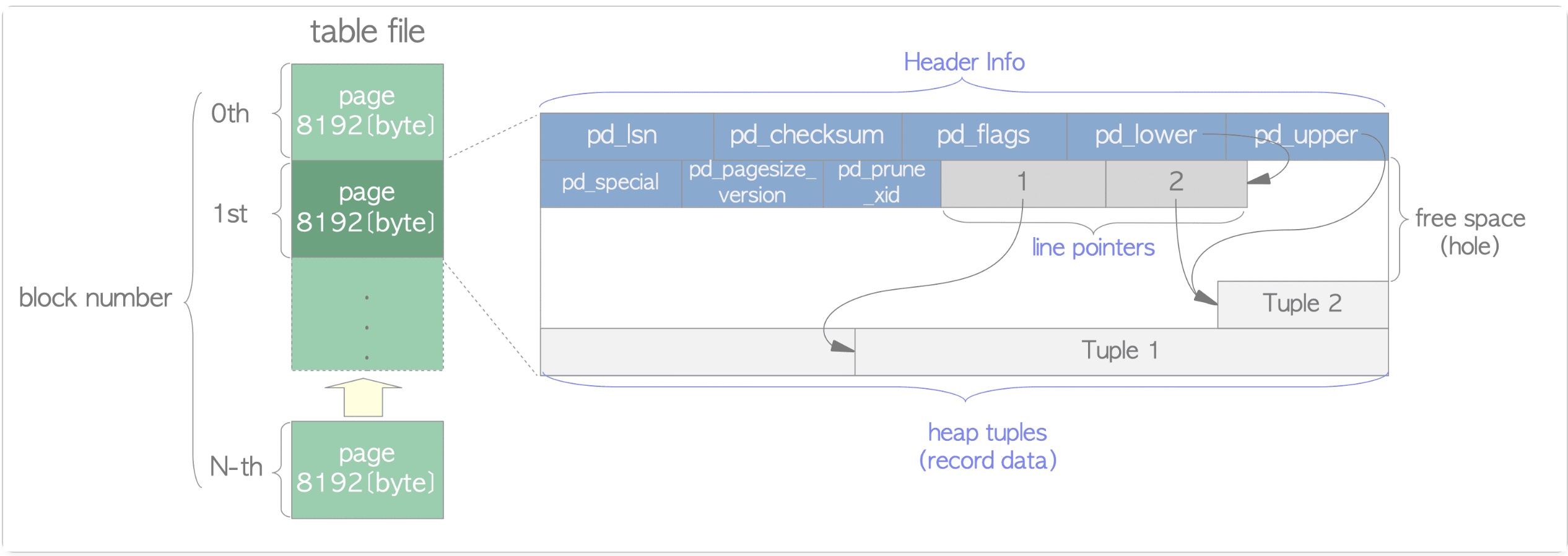
Indexes
Hash Index
Bitmap Index
- B+Tree Index
References:
- Indexes in PostgreSQL — 1
- Indexes in PostgreSQL — 2
- Indexes in PostgreSQL — 3 (Hash)
- Indexes in PostgreSQL — 4 (Btree)
- Indexes in PostgreSQL — 5 (GiST)
- Indexes in PostgreSQL — 6 (SP-GiST)
- Indexes in PostgreSQL — 7 (GIN)
- Indexes in PostgreSQL — 9 (BRIN)
Process
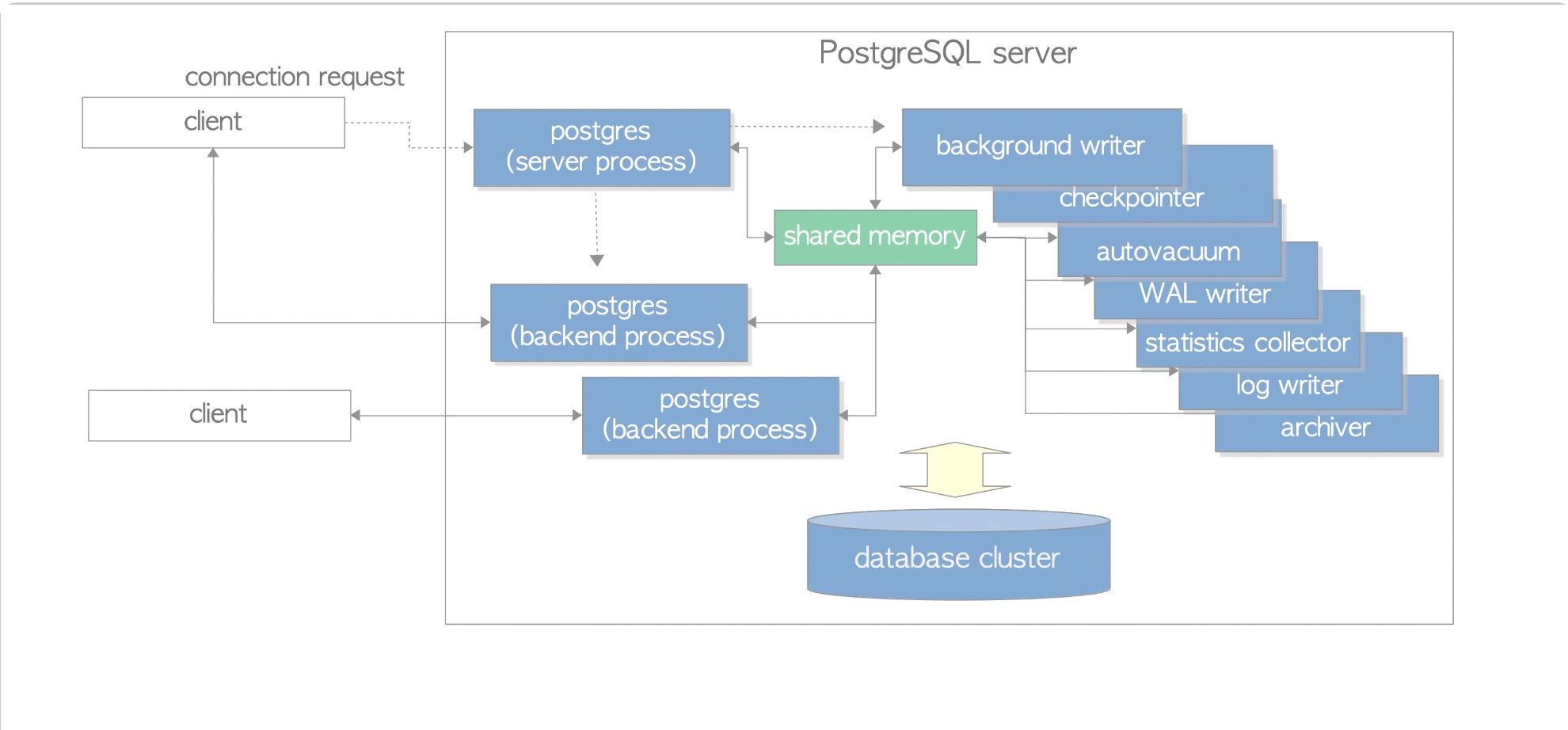
Postgres has following main processes:
Server process: parent of all processes. It starts the background processes, replication-associated processes, listens to port 5432 for client connection and starts a backend process for handling that client queries.
Backend process: Each backend process can access only one database. And each is initialized for one client connection. Postgres does not have a connection pool, if the users connect and deconnect frequently the performance is harmed. Usually there are some connection pool middleware to solve the problem.
Background process:

- Background worker process: like background process, but is created by user to do background works.
Memory
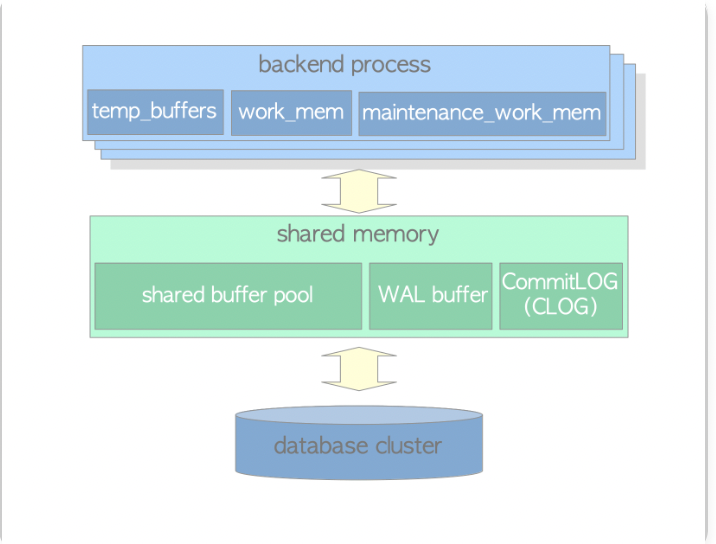
- Local Memory Area: Each backend process allocate a local memory area for query processing
- Work-mem: for sorting tuples for ORDER_BY and DISTINCT, and for joining tables for merge join and hash join
- maintainence work memory: for maintenance operations: VACUUM, REINDEX
- Temp buffer: store temporary tables
- Shared Memory Area
- shared buffer pool
- WAL buffer: is a buffering area of the WAL data before writing to a persistent storage.
- commit log: keeps the state of all transactions for the concurrency control mechanism
Query Processing
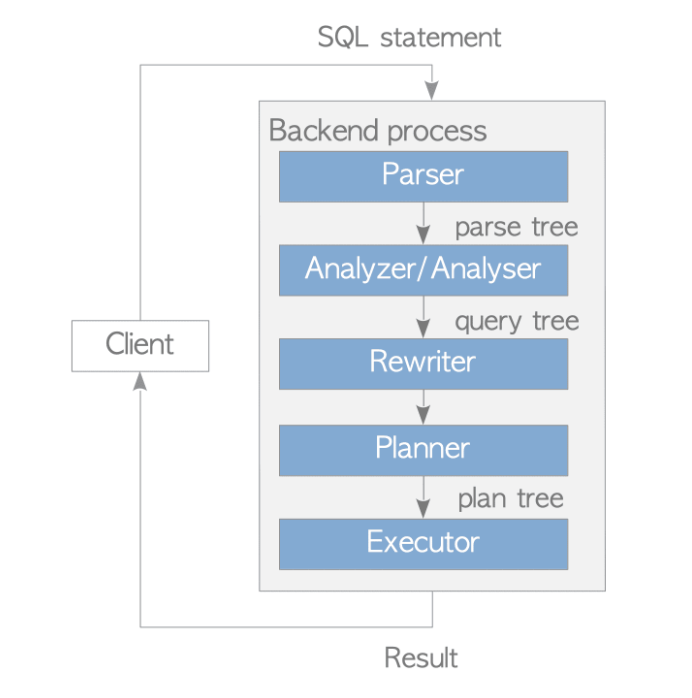
- Parser
It is like a frontend of compilers, creating a syntax tree and checking syntax.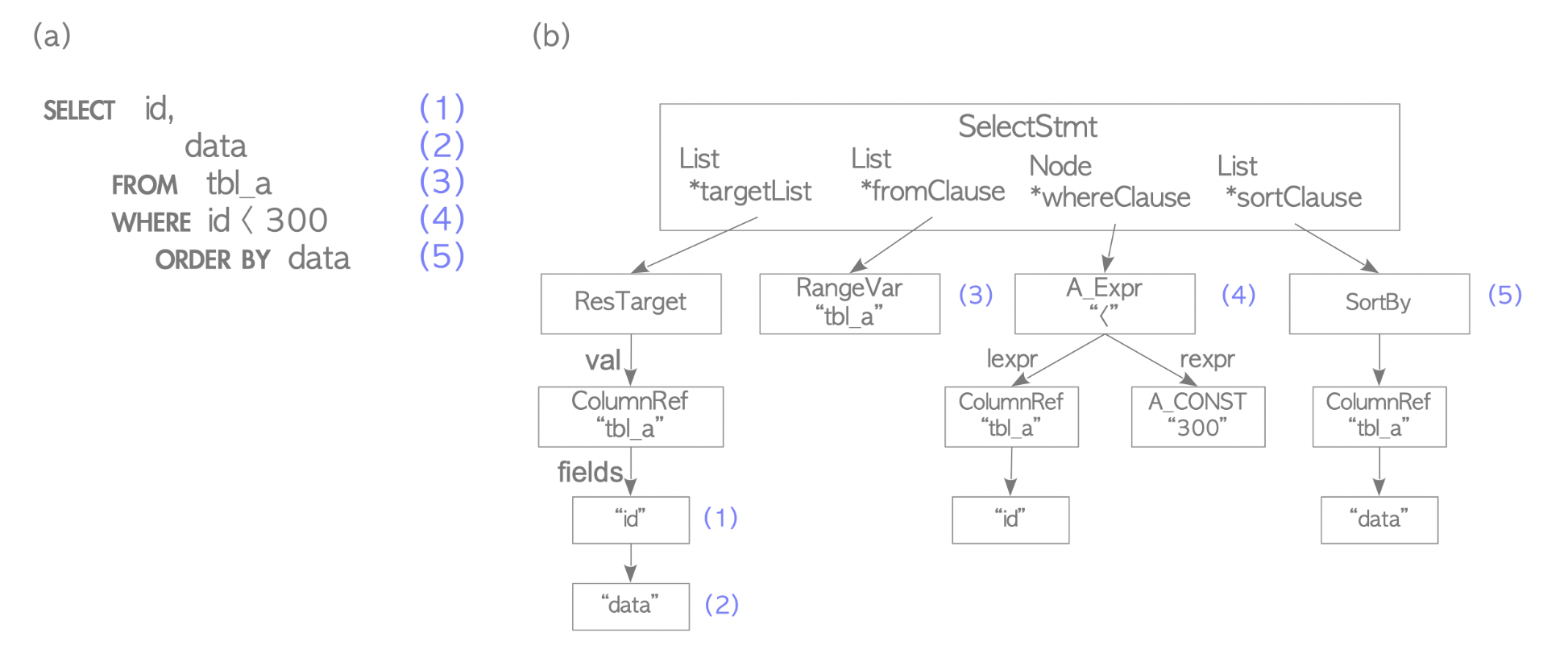
- Analyzer
Generate query tree with target tree, range table, join tree and sort clause.
- Rewriter
The rewriter is the system that realizes the rule system. For example, views related rules are applied through rewriter.
Planner
Executor
Cost Estimation
Postgres query optimization is based on cost, and costs are indicators to compare relative performance of operations (not real performance, it is estimated by certain calculations). Costs have the following types:
Start up
Start up is the cost expended before the first tuple is fetched. For example, index scan spends start up costs to read index files.
Run
The cost of fetching all tuples.
Total:Start up + Run
testdb=# ;
)
()
The above query’s startup cost is 0.00 and total cost is 145.00.
Sequential Scan Estimation:
$$ \begin{aligned} \text{'run cost'} &= \text{'cpu run cost'}+\text{'disk run cost'}\\ &= (\text{cpu\_ tuple\_cost}+\text{cpu\_operator\_cost})\times N_{tuplue}+\text{seq\_page\_cost} \times N_{page}, \end{aligned} $$
Index Scan Estimation:
startup cost
Although postgres have multiple index, they all use cost_index to estimate. $H_{index}$ is the height of the index tree.
$ \text{'start-up cost'}=\{ceil(\log_2(N_{index,tuple}))+(H_{index}+1)\times50\} \times \text{cpu\_operator\_cost}, $run cost
